



零距离接触NVIDIA GF100
第三代Streaming Multiprocessor
在前面我们介绍了,GF100总共拥有512个CUDA核心,大幅度领先于GT200架构。仅仅比较CUDA核心数量,GF100的性能就应该超过GT200。但是,GF100的革新并不会是简单的CUDA核心数量的提升,还有很多额外的改变。接下来,我们就以SM为主,介绍GF100核心架构上的变化。
NVIDIA显卡的CUDA核心只是一个功能单元,它主要进行浮点和整数的计算。而真正包含完整的调度机构、程序计数器、指令缓存的是SM。GF100的SM是NVIDIA的第三代设计,每个SM包含了32个CUDA核心,实际的单周期理论性能则提升了接近1倍甚至更多。在GF100的每个SM里,包含了两个Warp Scheduler和两个指令分发单元,允许两个Warp同时地发射和执行。
●32个CUDA核心
○GT200的四倍
●48/16KB共享缓存
○GT200的三倍
●16/48KB的L1缓存
○GT200没有L1
●改进的ISA
○32位整数运算
○IEEE-754 2008双精度浮点FMA运算
●4个纹理单元
●1个PolyMorph引擎
先进的缓存架构
GF100的缓存设计是NVIDIA的GF100的竞争优势所在,GF100的每一个SM中拥有64KB的可配置片上缓存,可以设置为48KB共享缓存加16KB L1缓存,也可以设置为16KB共享缓存加48KB L1缓存。在之前的GT200核心中,并没有L1缓存的设计。L1缓存可以用于处理寄存器溢出、堆栈操作和全局LD/ST。过去,GPU的寄存器如果发生溢出的话,会大幅度地增加存取时延。有了L1缓存以后,即使临时寄存器使用量增加,程序的性能表现也不至于大起大落。对于那些无法预知数据地址的算法,例如物理计算、光线追踪都可以从GF100的专用L1缓存设计中显著获益。共享缓存的设计则有利于多线程间数据重用,让程序把共享缓存当成缓存来使用,由软件负责实现数据的读写和一致性管理。而对那些没有使用共享缓存的应用程序来说,也可以直接从L1缓存中受益,显著缩减运行CUDA程序的时间。
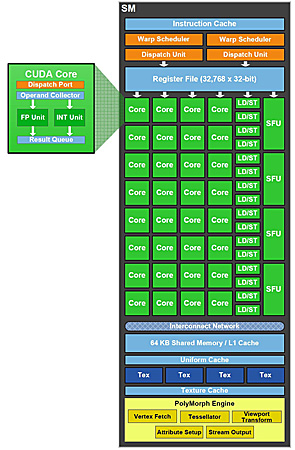
GF100 SM架构图
另外,GF100提供的一体化L2缓存达到了768KB,是GT200的三倍。L2缓存为传统的顶点、SM、Load/Store、纹理和ROP数据操作提供高速缓存。因此,GF100提供了更大的纹理覆盖和更强大的计算性能。
更精美的画面
GF100的采样模式在之前的CSAA(Coverage Sample Anti-aliasing,覆盖取样抗锯齿)模式上,又进行了改进。传统的MSAA模式不足以达到更高的采样数,CSAA将MSAA颜色和深度值(Color/Z)的取样点位置延伸到了被取样的Pixel之内,颜色值在被取样的Pixel点中心得到, 并且将Color和Z数据存放在缓存中。这样,我们能在保存同样的Color/Z数据下得到更多的取样点。

GT200的16X CSAA采样

GF100的32X CSAA采样
CSAA采样模式首次出现在G80上,现在在GF100上有所变化,采用了新的8X+24X CSAA模式。其中,新的CSAA进行了8X色彩采样和24X覆盖采样模式的组合,达到总共32X的采样模式。而且GF100上还使用了阿尔法覆盖模式,这在GT200中也没有实现。32X CSAA采样模式带来的直观的画面效果,就是在物体边缘更清晰,减小了噪点,同时更平滑。而在性能损失方面,采用32X CSAA采样模式的GF100显卡性能相比采用8X AA模式时仅低了7%。
GF100的游戏计算架构
在我们之前对GF100显卡的报道中,提到了GF100显卡在计算架构上的优异性。它已经不仅仅把注意力放到了3D渲染之上,而是通过特殊的架构设计,提高浮点、整数等计算能力。GF100拥有的CUDA并行计算架构,可以让更多的用户、更多的工作让GPU来完成。当然,计算能力的提升,也对游戏的性能提升有明显的帮助。
GF100支持CUDA C++、CUDA C、OpenCL、DirectCompute、PhysX和OptiX RAY Tracing等功能,使其在游戏中的AI计算、物理计算、顺序无关透明、光线追踪等方面,相对GT200都有显著的性能提升。

