



零距离接触NVIDIA GF100
 虽然早已闻其名,但是,NVIDIA的GF100显卡(GPU架构代号Fermi)一直难以和用户说“Hello”。在CES 2010展会上,MC记者除了深刻体会到NVIDIA 3D立体幻镜技术所刮起的3D旋风,更是作为中国大陆的唯一代表,一睹GF100显卡芳容,并拿到了NVIDIA官方透露的GF100显卡完整的规格和性能等信息。现在,我们就把这些信息第一时间传递给我们的读者。
虽然早已闻其名,但是,NVIDIA的GF100显卡(GPU架构代号Fermi)一直难以和用户说“Hello”。在CES 2010展会上,MC记者除了深刻体会到NVIDIA 3D立体幻镜技术所刮起的3D旋风,更是作为中国大陆的唯一代表,一睹GF100显卡芳容,并拿到了NVIDIA官方透露的GF100显卡完整的规格和性能等信息。现在,我们就把这些信息第一时间传递给我们的读者。
GF100显卡架构解读
Fermi,是NVIDIA新GPU架构的名称,基于该架构的显卡产品早被我们称作GT300,认为是GT200产品的延续。后来NVIDIA官方确认Fermi架构应用在GeForce系列显卡的正式代号为GF100。名称的变化正昭示了GF100显卡将有重大的跃进,为用户了带来更强的技术演进和创新的功能。那么,就让我们一起来了解GF100显卡的核心架构。
GF100核心架构
512个CUDA核心
16个几何单元
4个Raster单元
64个贴图单元
48个ROP单元
提供384bit GDDR5显存接口

从以上的数据看,GF100提供了数量更多的CUDA核心,GT200仅有240个CUDA核心,而GF100达到了512个。与GT200相比,GF100的架构中不再有TPC这一级的单位,而增加了一个叫做GPC的单位。SM依然存在,在GF100中每个GPC包含4个SM,每个SM有32个CUDA核心,而GT200的每个SM仅仅包含有8个CUDA核心,可以说GF100的每个SM的单精度计算能力比GT200的SM提高了3倍。相比较GT200核心,GF100拥有以下四点的性能改善:
1.几何性能大幅度提升
2.更优秀的图像质量
3.为游戏提供革命性的GPU Compute功能
4.强的游戏性能
几何性能大幅度提升
在游戏画面的生成过程中,我们一般看到的是3D画面的贴图,但是隐藏在贴图里面的还有3D画面的骨架——几何构图。3D画面的形成首先要构建几何构图,然后再进行渲染。在这之前,3D显卡的几何性能的提升过程是非常缓慢的,从GeForce FX 5800到GeForce GTX 285,显卡的像素渲染能力提升了超过150倍,但是几何性能仅仅提升了不到3倍。这源于API一直没有提供对几何构图的支持,DirectX 9和DirectX 10都不能通过GPU来创建几何图形。而在DirectX 11时代,GF100显卡和API提供了新的几何处理的功能——Tessellation,使得GF100拥有了相对GT200显卡超过8X的几何性能提升。
Tessellation如何工作
Tessellation是DirectX 11的重要特性之一,它的中文名称为镶嵌细分曲面技术。3D画面是由无数的三角形组成的,Tessellation技术可以在原本的三角形画面的基础上,再细分出无数的小三角形,然后再叠加位移贴图,如此一来得到细节更加丰富的画面。
Tessellation技术可以在极小的显存占用之下,生成原始模型的三角形顶点,接着通过特殊算法,在三角形之中自动拆分出更多的三角形,使得画面的精细程度得到提升。整个过程只需简单勾绘一个轮廓,剩下的就可以交给Tessellation技术自动拆嵌,大大提高效率。从而在节约显存开销的情况下,创造更多数量级的顶点,提升渲染速度。
在DirectX 11中,Tessellation的具体工作过程是如何的呢?在整个画面的形成过程中,首先是顶点着色器建立图像的顶点,然后经过修订后进入控制点的过程。控制点包括外壳着色(Hull Shader)、细分曲面(Tessellator)和域着色器(Domain Shader)三个阶段,在重点的Tessellator前后分别是外壳着色器和域着色器。外壳着色器将确定采用何种方法进行曲面细分,同时明确各控制点。接着在Tessellator里,根据外壳着色器确定的系数拆分曲面。后,在域着色器将贴图(u,v)坐标转换为(x,y,z,w),根据控制点或置换贴图的参数来控制这些新产生的点如何转移或坐标位移。每处理完一个点后,域着色器就会输出一个顶点,再进一步交由几何着色器来处理。
在下面的两幅图片中,我们可以看到没有经过Tessellation的图片,水面和岩石都非常平整,显然不够真实。而在经过Tessellation之后,画面的细腻程度得到了增加,特别是水面的拥有了涟漪感,山峰的岩石表面更加凹凸不平。

原始画面

经过Tessellation处理后的画面
那么,要实现Tessellation功能,GF100在硬件上做出了哪些改变或者进化呢?这主要是通过PolyMorph引擎和Raster引擎实现的。它们是GF100显卡中的特殊硬件,PolyMorph引擎主要完成世界空间的处理,完成顶点拾取、Tessellator、视点变换、属性设置和stream输出。而Raster引擎则完成屏幕空间处理,包括边缘设置、光栅、Z-Cull。以上两个部分的硬件就是GF100几何性能提升的关键。GF100总共包含了16个PolyMorph引擎和4个Raster引擎。每个SM包含一个PolyMorph引擎,每4个SM拥有一个Raster引擎。这些硬件上的设计,让GF100在进行Tessellation操作时,性能下降很少。在测试Demo里,打开Tessellation技术之后,帧率的下降幅度并不明显。
Tessellation性能对比
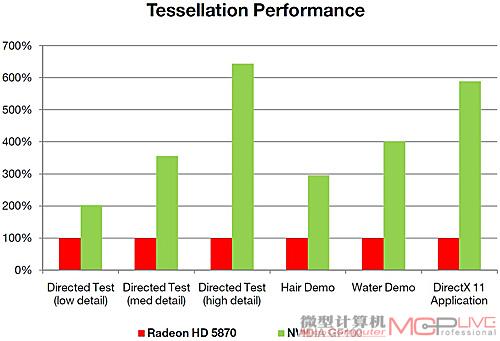
在GF100的媒体沟通会上,NVIDIA透露了GF100显卡在运行Tessellation测试DEMO时的性能,并对比了ATI的Radeon HD 5870显卡,本刊记者记录下了成绩,让大家对GF100的性能有一个初步的了解。
第三代Streaming Multiprocessor
在前面我们介绍了,GF100总共拥有512个CUDA核心,大幅度领先于GT200架构。仅仅比较CUDA核心数量,GF100的性能就应该超过GT200。但是,GF100的革新并不会是简单的CUDA核心数量的提升,还有很多额外的改变。接下来,我们就以SM为主,介绍GF100核心架构上的变化。
NVIDIA显卡的CUDA核心只是一个功能单元,它主要进行浮点和整数的计算。而真正包含完整的调度机构、程序计数器、指令缓存的是SM。GF100的SM是NVIDIA的第三代设计,每个SM包含了32个CUDA核心,实际的单周期理论性能则提升了接近1倍甚至更多。在GF100的每个SM里,包含了两个Warp Scheduler和两个指令分发单元,允许两个Warp同时地发射和执行。
●32个CUDA核心
○GT200的四倍
●48/16KB共享缓存
○GT200的三倍
●16/48KB的L1缓存
○GT200没有L1
●改进的ISA
○32位整数运算
○IEEE-754 2008双精度浮点FMA运算
●4个纹理单元
●1个PolyMorph引擎
先进的缓存架构
GF100的缓存设计是NVIDIA的GF100的竞争优势所在,GF100的每一个SM中拥有64KB的可配置片上缓存,可以设置为48KB共享缓存加16KB L1缓存,也可以设置为16KB共享缓存加48KB L1缓存。在之前的GT200核心中,并没有L1缓存的设计。L1缓存可以用于处理寄存器溢出、堆栈操作和全局LD/ST。过去,GPU的寄存器如果发生溢出的话,会大幅度地增加存取时延。有了L1缓存以后,即使临时寄存器使用量增加,程序的性能表现也不至于大起大落。对于那些无法预知数据地址的算法,例如物理计算、光线追踪都可以从GF100的专用L1缓存设计中显著获益。共享缓存的设计则有利于多线程间数据重用,让程序把共享缓存当成缓存来使用,由软件负责实现数据的读写和一致性管理。而对那些没有使用共享缓存的应用程序来说,也可以直接从L1缓存中受益,显著缩减运行CUDA程序的时间。
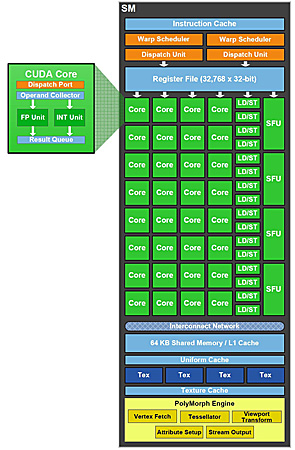
GF100 SM架构图
另外,GF100提供的一体化L2缓存达到了768KB,是GT200的三倍。L2缓存为传统的顶点、SM、Load/Store、纹理和ROP数据操作提供高速缓存。因此,GF100提供了更大的纹理覆盖和更强大的计算性能。
更精美的画面
GF100的采样模式在之前的CSAA(Coverage Sample Anti-aliasing,覆盖取样抗锯齿)模式上,又进行了改进。传统的MSAA模式不足以达到更高的采样数,CSAA将MSAA颜色和深度值(Color/Z)的取样点位置延伸到了被取样的Pixel之内,颜色值在被取样的Pixel点中心得到, 并且将Color和Z数据存放在缓存中。这样,我们能在保存同样的Color/Z数据下得到更多的取样点。

GT200的16X CSAA采样

GF100的32X CSAA采样
CSAA采样模式首次出现在G80上,现在在GF100上有所变化,采用了新的8X+24X CSAA模式。其中,新的CSAA进行了8X色彩采样和24X覆盖采样模式的组合,达到总共32X的采样模式。而且GF100上还使用了阿尔法覆盖模式,这在GT200中也没有实现。32X CSAA采样模式带来的直观的画面效果,就是在物体边缘更清晰,减小了噪点,同时更平滑。而在性能损失方面,采用32X CSAA采样模式的GF100显卡性能相比采用8X AA模式时仅低了7%。
GF100的游戏计算架构
在我们之前对GF100显卡的报道中,提到了GF100显卡在计算架构上的优异性。它已经不仅仅把注意力放到了3D渲染之上,而是通过特殊的架构设计,提高浮点、整数等计算能力。GF100拥有的CUDA并行计算架构,可以让更多的用户、更多的工作让GPU来完成。当然,计算能力的提升,也对游戏的性能提升有明显的帮助。
GF100支持CUDA C++、CUDA C、OpenCL、DirectCompute、PhysX和OptiX RAY Tracing等功能,使其在游戏中的AI计算、物理计算、顺序无关透明、光线追踪等方面,相对GT200都有显著的性能提升。
GF100的性能展示
在了解了GF100显卡的新特性之后,我们早已对它充满了期待,但是性能到底表现如何呢?
|
Farcry2(DirectX 10,1920×1200) | ||
|
|
GT200 |
GF100 |
|
平均帧率 |
49.85 |
84.04 |
|
大帧率 |
73.57 |
125.46 |
|
小帧率 |
23.09 |
65.33 |
|
Dark Void(PhysX,1920×1200) | ||
|
|
GT200 |
GF100 |
|
小帧率 |
28.39 |
49.92 |
|
平均帧率 |
37.94 |
77.03 |
|
光线追踪 |
GT200 |
GF100 |
|
帧率 |
0.233 |
0.632 |
在这次CES会议上,NVIDIA还为我们现场展示了GF100的3D性能。从3D游戏的测试性能来看,GF100相比GT200有非常大的性能提升,平均帧率提升幅度甚至超过了50%。再对比我们之前报道的GT200和Radeon HD 5870对比成绩,GF100的性能提升幅度非常大,超过Radeon HD 5870成为单芯片显卡中强的产品。而从光线追踪Demo的测试成绩来看,GF100得益于先进的架构设计,性能接近GT200的三倍。
GF100显卡的新应用
从一开始宣传的时候,GF100的重点就不在3D性能,而是在高性能的计算能力上。GF100不仅仅是用于3D游戏的显卡,还是一款功能强大的“专业”显卡。GF100的新功能包括PhysX&APEX软件应用、GPU开发环境和3D Vision应用。目前,NVIDIA显卡的PhysX物理功能主要是用在游戏中,计算物体的物理效果。NVIDIA APEX被设计为一个模块化的框架,能够与现有的PhysX软件开发包一起使用,使开发人员能够轻松地在其游戏中添加细腻的物理效果。帮助开发人员加快设计新游戏的速度,降低开发成本。
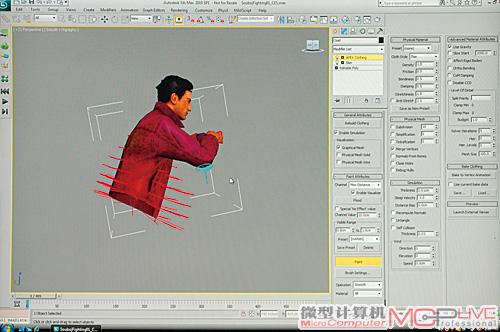
Autodesk 3ds Max 2010中,可以使用PhysX插件,设计动画的物理效果。
图中正在为衣服设置物理效果,下部的衣角部分的物理量需要设置得更高一些。
NVIDIA还推出了NVIDIA Nexus,它是业内首款面向大规模并行计算的开发环境,现已集成在Microsoft Visual Studio之中。Microsoft Visual Studio是世界上流行的开发环境,用于开发基于Windows的解决方案以及Web应用程序与服务。Nexus包含了先进工具,可同时对图形处理器(GPU)与中央处理器(CPU)的效率、性能以及速度进行分析,从而让开发人员能够即时了解协同处理对其应用程序所带来的影响。
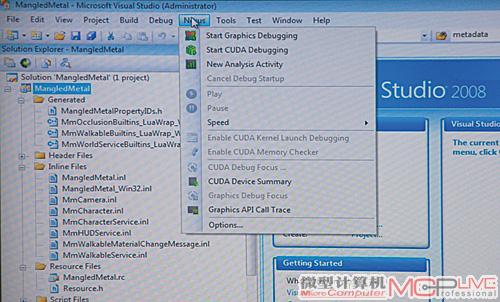
利用NVIDIA Nexus进行软件调试
由于GF100显卡拥有非常强悍的3D性能,因此,游戏方式也可以得到扩展。NVIDIA在本次CES上展示了3D Vision surround功能,就是用三个屏幕拼接在一起,享受超宽游戏画面的同时,还同时辅以3D立体画面,更进一步增强游戏的真实感。目前2560×1600@60Hz画面的数据处理量为4M像素,1920×1080@120Hz三个画面组建3D Vison surround功能则总共需要更大的数据量。再加上PhysX、Tessellation等功能,要实现流畅的运行,需要非常强劲的性能,GF100显卡组建的SLI系统则能够完美实现这强的立体游戏环境。NVIDIA 3D Vision surround已经成为本次CES展会上的亮点,三屏加立体效果,每一个玩家都能得到真实的游戏体验。
结语
很荣幸,本刊记者能够率先领略到GF100显卡的真实性能,而且也非常期待这款不仅仅是传统意义上的“3D显卡”的高性能计算产品。然而,NVIDIA也仅仅是揭开了GF100的一层面纱。究竟GF100显卡的功耗如何?3D性能能够达到怎样的高度?CUDA计算能力提升幅度是多少?我们还有很多疑问,留待其三月和消费者正式见面后的详细评测中解决。也请各位读者继续关注MC对GF100显卡的相关报道!

