



在“内存墙”的困扰中寻找出路
现实中如何降低内存等待时间
由于提升内存的工作频率难度很大,因此在降低内存等待时间时,厂商并非直接改进内存,而是将目光集中在如何优化处理器对内存的使用上。从新的Intel Core i7和AMD Phenom Ⅱ等四核处理器中可以看到,用于降低内存等待时间的缓存和预取、多线程和乱序执行等技术被进一步改进,同时处理器集成内存控制器进一步降低了内存等待时间。
1.增强的多级缓存和预取技术
当处理器需要读取数据时,首先会在自己的缓存中查找,如果找到就高速读取到核心中处理,这被称为“缓存命中”,访问缓存的命中次数与总访问次数的比率称为“命中率”(Hit Rate)。利用缓存有效降低内存等待时间的关键是要尽可能提高缓存命中率,目前多核处理器缓存技术的发展趋势是采用更大容量的、更多级的缓存结构,以及更为有效的缓存管理和数据预取技术。
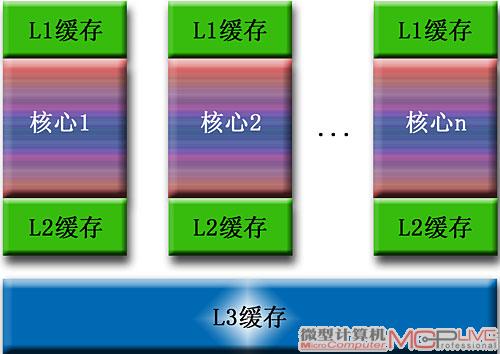
多核处理器的三级缓存设计
增强的大容量多级缓存设计:增加缓存的容量可保存更多的数据,显然能提高缓存命中率。而增加缓存的层级是提高缓存命中率的另一种途径,例如两级缓存中L1、L2的理论命中率均为80%左右,两级缓存总的命中率大约为(80+0.2×80)%=96%,依此类推缓存级层越多命中率越高。因此在Core i7和Phenom Ⅱ等新一代四核处理器中,都采用了大容量的三级缓存结构,每个处理器核心都具有独立的L1、L2两级缓存,共享大容量L3缓存,其中Phenom Ⅱ的L3缓存容量为6MB,Core i7的L3缓存容量更达到了8MB,并且Core i7的微架构中还采用了易扩展设计,为今后继续增大L3缓存容量埋下了伏笔。
更有效的缓存管理技术:对于多核处理器的缓存系统而言,采用更有效的缓存管理技术也是非常重要的。例如Core i7采用了“先进的智能缓存”(Advanced Smart Cache,ASC)技术,可根据各个核心的处理负载动态分配共享的L3缓存,从而提高了各核心从共享的L3中读取数据的效率。
ASC对共享的L3缓存采用了“包容性”(Inclusive)机制,即L1、L2中的数据都包含在L3中,当一个核心访问L3没有命中时,会立即转向访问内存读取数据,从而有效降低了继续查找L1、L2所产生的侦听通信量和时间延迟。ASC还引入了基于L3包容性机制的“侦听过滤”(Snoop Filter)技术,当处理器访问L3命中时并不直接从速度较慢的L3读取所需数据,而是转向速度更快的L1或L2读取,从而减少了处理器获取数据的时间。
更有效的数据预取技术:即基于一定的预测机制,把处理器可能用到的数据预先从内存读取到缓存中,从而提高缓存命中率。数据预取可通过处理器内置的预取器(Prefetcher)以硬件预取方式实现,也可在程序中调用处理器的预取指令以软件预取方式实现。例如Phenom Ⅱ的每个核心有1个指令预取器和1个数据预取器,并采用了“先进的内存预取器”(Advanced Memory Prefetcher,AMP)技术。AMP可绕过L2将数据直接从内存读取到L1中,避免了L2的延时,也减轻了L2的负载。AMP技术具有“自适应预取”(Adaptive Prefetch,AP)机制,可基于对内存请求的监测和分析预取任何地址的数据。AMP还引入了置于内存控制器中的“DRAM预取器”,可配合AP机制监测整体的内存访问请求,把可能用到的数据预先提取到DRAM预取缓冲器中,以便在需要时以更快的速度传送这些数据。
2.多线程和乱序执行技术
“超线程”(Hyper-Threading,HT)也称作“同步多线程”(Simultaneous Multi-Threading,SMT)。HT技术起源于Pentium 4处理器,由于处理器核心的寄存器等多个部件都配置了两套,所以可以在处理器中增加一个线程调度单元,将两个线程的指令序列分配到这些两套部件中,就相当于同时激活了两个线程。当一个线程因等待数据而处于停顿状态时,立即让另一线程执行任务,从而避免了处理器资源被闲置,提升了处理效率。在Core i7处理器中,同样使用了HT技术,并且指令执行机制更高效,缓存容量和内存带宽更大,配合高度线程化的应用程序,Core i7处理器的HT技术在降低内存等待时间、提升整体的处理效率方面更为有效。
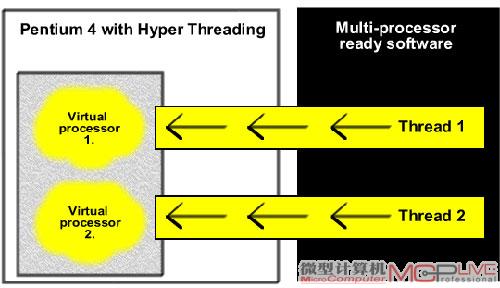
著名的“超线程”HT技术的实质就是降低内存等待时间
乱序执行(Out-of-Order Execution,OOOE)是一种指令级并行计算的处理器设计。支持OOOE的处理器可以不按程序中原有的指令顺序执行任务,而是通过OOOE引擎监测和分析哪些处理器单元会被闲置、程序中的哪些指令可不按顺序提前执行,再将这些指令分配给闲置的处理单元开始执行,然后将其运算结果按程序中的原有顺序重新排列。OOOE利用并行处理机制避免了处理器资源的闲置,与HT技术一道提升了处理器的整体处理效率。新的多核处理器均强化了OOOE的设计,例如Core i7中“重排序缓冲器”(Re-Order Buffer,ROB)等关键OOOE单元的规模被明显加大,Intel“智能内存访问”(Smart Memory Access,SMA)技术则提高了OOOE的效率。SMA除了指令级的预取管理功能之外,还具有“内存数据相关性预测”(Memory Disambiguation)机制,能对指令之间的相关性进行分析,智能化地预测将要执行的指令,并提前将其所需数据预取到缓存中,使这些指令执行时能快速获取所需数据,从而有效降低了等待数据的延迟。
3.集成式内存控制器
“集成式内存控制器”(Integrated Memory Controller,IMC)技术大家应该也不陌生。在消费级处理器上,该技术早应用在AMD Athlon处理器上。它将原来北桥芯片组中的内存控制器集成在处理器芯片中,缩短了处理器访问内存的物理路径,从而降低了读取内存的延迟;同时可使内存控制器与处理器运行在相同的时钟频率下,能够在很大程度上减少处理器访问内存数据的等待时间。
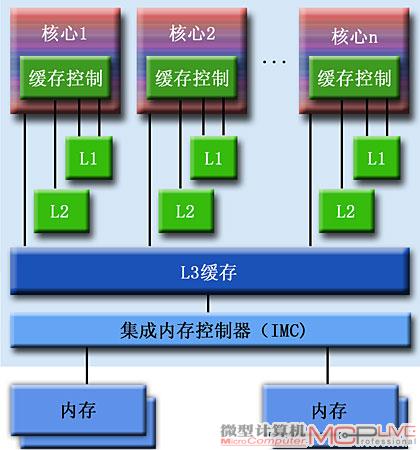
集成内存控制器的多核处理器
在Phenom Ⅱ处理器中,集成的是双通道DDR2 1066和DDR3 1333内存控制器;Core i7处理器则首次集成了三通道DDR3 1333内存控制器。再配合AMD HyperTransport 3.0、Intel QuickPath Interconnect(QPI)总线技术,可有效提升各核心对内存的存取效率。

